System Design of Netflix: Video Storage & Distribution, Playback, Recommendation, and Search & Discovery
A Detailed Exploration of User & Social Graph, Content, Feed, Engagement, Media, and Search & Discovery.
 by Ramesndra Kumar
April 02, 2025
by Ramesndra Kumar
April 02, 2025
About the author: Principal Engineer at Paytm, ex-Microsoft, system design coach, and mentor for top tech roles. Book time with them here.
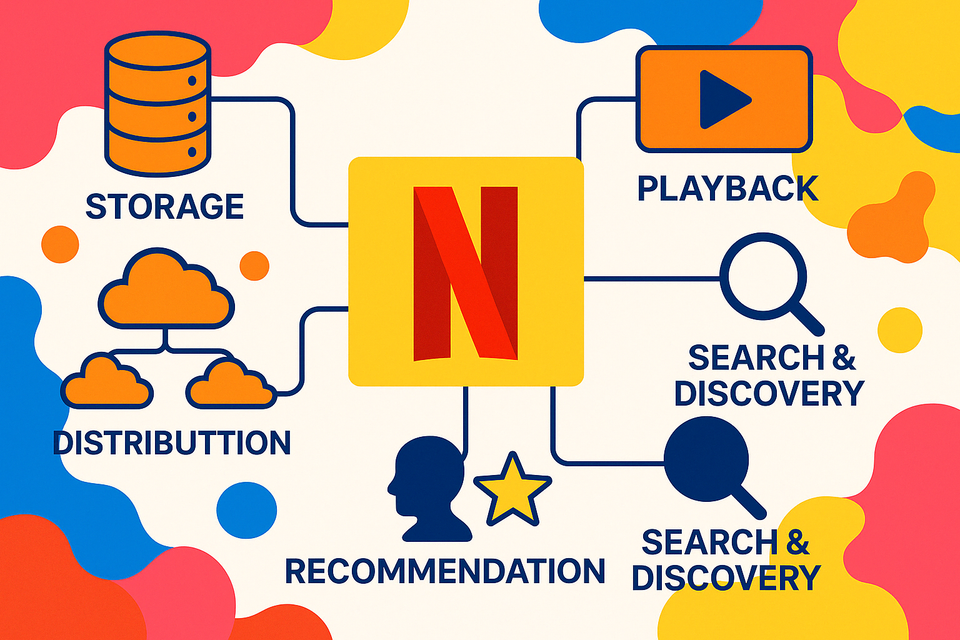
Designing a Netflix-like platform requires consideration of the fundamental building blocks that store, encode, distribute, and play video content while providing personalized recommendations and fast search functionality. This article addresses the core functional requirements—video storage & distribution, playback system, recommendation engine, and search & discovery—that form the backbone of a large-scale video-on-demand (VOD) ecosystem. By adhering to these pillars, we build a scalable infrastructure capable of serving millions of concurrent streams.
We will cover payment system in a separate blog soon, so it’s not covered here.
1. Understand Question as User
We aim to design a Netflix - like VOD system that addresses the following critical components:
1. Video Storage & Distribution
-
Ingest, encode, and store media files.
-
Distribute content globally with low latency and high availability.
2. Video Playback System
-
Provide adaptive bitrate streaming for a smooth user experience.
-
Ensure proper DRM (digital rights management) and secure playback.
3. Recommendation Engine
-
Personalize content suggestions based on user behavior and history.
-
Handle large-scale user-event data for continuous model updates.
4. Search & Discovery
-
Allow users to quickly find content by title, genre, actors.
-
Provide real-time or near real-time indexing of newly added or popular content.
As with other large-scale streaming services, we want a highly scalable, fault-tolerant, and globally accessible platform that can handle millions of concurrent viewers, handle huge content libraries, and provide top-tier streaming quality around the world.
Check out more insights on system design
2. Requirement Gathering
2.1 Functional Requirements (FR)
1. Video Storage & Distribution
-
Efficiently ingest and store large video files (movies, TV series).
-
Transcode video into multiple bitrates/resolutions for adaptive streaming.
-
Leverage CDN (Content Delivery Network) or a custom edge network for distribution.
-
Handle region-based licensing, geo-restrictions.
2. Video Playback System
-
Adaptive bitrate streaming (ABR) to accommodate varying network conditions.
-
Support multi-platform playback (web, mobile, smart TVs, etc.).
-
DRM solutions for content protection (Widevine, FairPlay, PlayReady).
-
Track user watch progress and handle resume functionality.
3. Recommendation Engine
-
Collect user interaction data (views, clicks, likes) to build user profiles.
-
Provide personalized content suggestions with collaborative filtering, content-based or hybrid approaches.
-
Continuously update recommendations in real time or near real time as users watch more content.
4. Search & Discovery
-
Fast indexing and retrieval of titles, genres, and metadata.
-
Support advanced filtering (e.g., release year, cast, user ratings).
-
Provide real-time or near real-time suggestions for trending or newly added content.
5. Logging & Monitoring
-
Collect usage metrics (stream counts, streaming errors).
-
Track system health and performance across microservices.
-
Provide dashboards for real-time observability.
2.2 Non-Functional Requirements (NFR)
-
Scalability & Low Latency: Handle millions of concurrent streams, with near-instant content start time.
-
Reliability: Minimal downtime; no dropped streams or partial content.
-
Security & DRM: Protect licensed content from unauthorized access or piracy.
-
Global Accessibility: Multi-region deployments and robust CDN coverage.
-
Fault Tolerance: Survive data center or region failures.
-
Observability: Fine-grained logging, metrics, and system tracing for quick issue detection.
2.3 Out of Scope
-
Payment/Billing system (subscription management).
-
Detailed content production pipelines or studio workflows.
-
Offline downloads or advanced bandwidth optimization (beyond standard adaptive streaming).
3. BOE Calculations / Capacity Estimations
1. Content Size
-
A typical HD movie might be ~2–3 GB after encoding; thousands of titles → multiple petabytes total.
-
4K or higher resolution multiplies storage needs significantly.
2. Concurrent Streams
-
Suppose 100 million daily active users (DAU) with 10% peak concurrency → ~10 million concurrent streams at peak.
-
Each stream requiring ~3–5 Mbps for HD or ~15–25 Mbps for 4K (adaptive). Must ensure CDN edges can deliver that scale.
3. Data Throughput
-
10 million concurrent HD streams at 5 Mbps → 50 Tbps total global throughput at peak.
-
This mandates a widespread global CDN or partnership with multiple edges.
4. Recommendation Data
-
If 100 million users, each generating multiple events (clicks, watch completions, ratings) daily → billions of events/day.
-
Storing these logs for real-time analytics requires robust streaming data infrastructure (e.g., Kafka).
5. Search & Discovery
-
Catalog size: tens or hundreds of thousands of titles. This is smaller than a massive search index, so feasible to do near real-time indexing.
-
QPS could be hundreds of thousands of search queries per second at peak.
4. Approach “Think-Out-Loud” (High-Level Design)
4.1 Architecture Overview
A microservices approach, each focusing on a core function:
1. Content Ingestion & Encoding Service – Upload original video files, transcode them, store in master storage.
2. CDN/Delivery Service – Serve streams from edge nodes with caching and load balancing.
3. Playback Service – Manages streaming manifests (HLS/DASH), DRM integration, session state.
4. Recommendation Engine – Aggregates user data, generates personalized lists.
5. Search & Discovery Service – Indexes content metadata, returns quick search results.
6. User & Session Service – Tracks user profiles, watch history, session info.
7. Analytics & Logging Service – Collects watch events, logs, metrics for system health and personalization.
Other supporting services might include authentication, device management, etc.
4.2 Data Consistency vs. Real-Time Updates
-
Playback: Must provide consistent, uninterrupted streaming (eventual consistency is fine for newly released content).
-
Recommendation: Often near real-time or batch-based. Some updates are quick (new watch events), others nightly.
-
Search Index: Must be updated promptly when new content is released but can tolerate slight indexing delays.
4.3 Security & Privacy Considerations
-
DRM: Required to protect licensed content.
-
Data Encryption: TLS for streaming, possibly encryption at rest for content.
-
Access Control: Some content may be geo-blocked or restricted by user subscription tier.
-
User Privacy: Comply with GDPR for data retention and usage logs.
5. Databases & Rationale
1. Content Metadata DB
-
Use Case: Titles, descriptions, cast, genre, etc.
-
Chosen DB: Relational or NoSQL. A structured relational DB (e.g., PostgreSQL) can handle well-defined metadata.
-
Why: Joins between cast, genres, and titles are common. Or a flexible NoSQL (e.g., MongoDB) if schema changes frequently.
2. Media Storage
-
Use Case: Storing large encoded video files.
-
Chosen DB: Object storage (e.g., AWS S3 or on-prem HDFS).
-
Why: Suited for large binary files, high durability, scalable.
3. CDN Edge Servers
-
Use Case: Global distribution, caching video segments for quick user access.
-
Chosen DB: Not a traditional DB, but ephemeral caching at edges.
-
Why: Minimizes latency and backbone bandwidth.
4. Recommendation Data Store
-
Use Case: User interactions (ratings, watch history), item-item correlations.
-
Chosen DB: Combination of NoSQL (e.g., Cassandra) for user-event writes plus a graph or specialized store for collaborative filtering.
-
Why: Large-scale write throughput, horizontal scalability.
5. Search Index
-
Use Case: Full-text search on titles, cast, keywords, plus real-time updates for new content.
-
Chosen DB: Elasticsearch or Solr.
-
Why: Fast text-based queries, highlight features, fuzzy matching, faceted search.
6. Analytics & Logging
-
Use Case: Collect streaming events, logs, metrics.
-
Chosen DB: Time-series or big data pipeline (Kafka → Spark/Hadoop → data warehouse).
-
Why: High ingestion rate, offline analytics, real-time dashboards.
6. APIs
Below are representative endpoints for each microservice.
6.1 Content Ingestion & Encoding Service
POST /content/ingest
Payload: { title, fileLocation, metadata }
Response: 201 Created { contentId, status="UPLOADING" }
POST /content/transcode
Payload: { contentId, encodingProfiles: [...] }
Response: 202 Accepted { jobId, status="TRANSCODING" }
6.2 Playback Service
GET /playback/start
Query Params: ?contentId=...&bitrate=...
Response: { streamUrl, drmLicenseInfo, sessionId }
POST /playback/heartbeat
Payload: { sessionId, currentPosition }
Response: 200 OK
6.3 CDN/Delivery
Typically no direct user-facing API; content is served via edge endpoints like:
GET /cdn/<region>/<contentId>/<bitrateSegment>.ts
6.4 Recommendation Engine
GET /recommendations
Query Params: ?userId=...
Response: [ { contentId, rankScore }, ... ]
POST /recommendations/feedback
Payload: { userId, contentId, action: "VIEW"|"LIKE"|"DISLIKE" }
Response: 200 OK
6.5 Search & Discovery
GET /search
Query Params: ?query=...&genre=...&limit=...
Response: [ { contentId, title, snippet }, ... ]
6.6 Analytics & Logging
(Internal) POST /logs/bulk
(Internal) GET /metrics
7. Deep Dive into Core Services
In this deep dive, we explore the responsibilities, core components, and common corner cases for five essential services: (A) Video Storage & Distribution, (B) Video Playback System, (C) Recommendation Engine, (D) Search & Discovery, and (E) Monitoring & Logging. Each of these areas addresses distinct functions that together form the backbone of a successful video-on-demand system.
A. Video Storage & Distribution
Responsibilities
- Ingest raw videos, encode them into multiple resolutions/bitrates: The platform must take large media files—possibly at very high master quality—and convert them into formats suitable for streaming. This includes transcoding or encoding at varying bitrates (e.g., 240p, 480p, 720p, 1080p, 4K) to accommodate users with different bandwidth capacities.
- Replicate final streams to CDN edges: After encoding is complete, the resulting video segments are uploaded to object storage or an origin server and then pushed or pulled to edge servers around the globe. The CDN ensures that viewers in distant regions can watch content with minimal latency and buffering.
- Ensure regional licensing and compliance: Content licensing deals often restrict viewership by geographic location or by user subscription tier. Video Storage & Distribution must account for these constraints, preventing unauthorized access in unlicensed regions.
Core Components
- Encoding Pipeline: Typically uses a set of distributed or cloud-based transcoders. Many systems rely on FFmpeg under the hood, but at large scale, containerization (e.g., Docker/Kubernetes) is employed for elasticity. When a new video is ingested, a “job” is created that splits the source file into small chunks, encodes them into multiple profiles, and packages them into streaming-friendly formats such as HLS or MPEG-DASH.
- Object Storage: Once each rendition is generated, the segments are placed in a high-durability, scalable store such as Amazon S3, Google Cloud Storage, or an on-premises system like HDFS. This central repository serves as the “origin,” from which downstream systems, including the CDN, fetch content.
- CDN: Content Delivery Networks cache frequently accessed video segments at edge locations. A user in Europe can fetch segments from a local European POP (Point of Presence), thus avoiding transcontinental latency. Some platforms create their own private CDN; others leverage commercial providers. The CDN typically uses a caching policy where the first request to a segment on a given edge node is fetched from the origin, then stored locally for subsequent requests.
Handling Corner Cases
- Network Congestion: No matter how well the segments are distributed, regional network congestion may still occur. Modern streaming protocols use adaptive bitrate streaming (ABR) to mitigate issues. Even though Storage & Distribution focuses on making all renditions available, the actual segment chosen depends on the user’s bandwidth as determined in real time.
- Geo-Blocking: The system enforces region-based restrictions if content is not licensed in certain territories. This can involve rejecting requests at the CDN or origin if the user’s IP is outside authorized regions, or providing different catalogs based on location.
- Encoding Queues: When many new titles or episodes arrive simultaneously—especially around major content dumps—there can be a backlog of encoding jobs. A properly designed pipeline must scale horizontally by spinning up additional transcoding workers. Otherwise, new content might take too long to become available in all relevant bitrates.
Detailed Discussion
At scale, Video Storage & Distribution has to handle petabytes to exabytes of data, especially when 4K and HDR content is part of the library. This means that the system must think carefully about cost-optimization, caching policies, redundancy, and data transfer overhead. For example, storing multiple resolutions of every show or movie can explode storage needs. Meanwhile, content popularity follows a long-tail pattern, where certain popular shows drive most of the streaming traffic. To optimize, the platform may pre-distribute the highest-demand content to edge nodes worldwide, while lesser-watched titles rely on the standard CDN fetch-on-demand model.
For large streaming services, a robust pipeline orchestrator is essential to track the lifecycle of each piece of content. That pipeline orchestrator typically includes a workflow manager that monitors progress, retries failed transcodes, and sends alerts if any step remains stuck or fails repeatedly. Scalability here is crucial: Some new releases require tens of thousands of encoding jobs to produce region-specific languages, subtitles, or multiple DRMs. In short, Video Storage & Distribution must be a carefully architected subsystem that focuses on reliability, high throughput, cost-effectiveness, and global coverage.
B. Video Playback System
Responsibilities
- Serve manifest files (HLS, MPEG-DASH): Each video is segmented, and the client player needs a manifest (e.g., .m3u8 or .mpd) that lists the available segments, bitrates, and durations.
- Integrate DRM keys for secure playback: The system coordinates license acquisition to ensure that only authorized devices can decrypt video streams.
- Track user watch progress: Users can pause on one device and resume on another; the system stores their current playback position.
Core Components
- Playback Orchestrator: Determines which segments to serve based on the device and network conditions.
- DRM Integration: Handles communication with license servers (e.g., Widevine, FairPlay, PlayReady).
- Session Tracking: Uses tokens or session IDs to track viewing activity, playback status, and user behavior.
Handling Corner Cases
- Buffering: Adaptive bitrate streaming adjusts quality based on bandwidth to ensure smooth playback.
- DRM Failures: If a license server is unavailable or a device doesn't support DRM, fallback logic or user messaging is needed.
- Resume Points: The system remembers where the user left off and resumes playback accordingly.
Detailed Discussion
Playback logic lives primarily on the client, but the server manages manifests, licenses, and playback sessions. Multi-DRM support ensures broad compatibility. Playback metrics help identify performance issues like buffering or early drop-offs.
Data from the playback system feeds into analytics and recommendation engines. This system must be responsive, secure, and able to handle millions of concurrent users across devices.
C. Recommendation Engine
Responsibilities
- Collect user watch data to build profiles: Includes plays, likes, skips, and ratings to track interests and patterns.
- Use collaborative filtering or ML algorithms: Suggests content using similarity-based or content-based models.
- Continuously update recommendations: Incorporates real-time activity and historical patterns for personalization.
Core Components
- Event Pipeline: Streams user interactions through systems like [Apache Kafka](https://kafka.apache.org/?utm_campaign=blog_promotion&utm_medium=cpc&utm_source=article) for logging and processing.
- Batch Model Training: Uses Spark, TensorFlow, or similar tools to generate recommendations offline.
- Online Inference: Returns fast results using Redis, Cassandra, or in-memory stores.
Handling Corner Cases
- Cold Start: New users see curated or trending content until enough data is available.
- Long-Tail Content: Occasionally surfaced to support niche interests and content discovery.
- Feedback Loops: Models must prevent overfitting or repetition by factoring in negative engagement.
Detailed Discussion
Recommendation engines blend real-time and batch processing to serve fresh, relevant suggestions. Hybrid models combining collaborative filtering and metadata features produce balanced recommendations.
Infrastructure must scale to handle billions of daily events, hundreds of millions of profiles, and quick refresh times. The goal is to improve engagement by surfacing the right content at the right time.
D. Search & Discovery
Responsibilities
- Index all content metadata: Includes titles, cast, genre, year, ratings, and more for quick retrieval.
- Provide fast keyword search: Users expect results in under 300ms for smooth experience.
- Highlight trending and new content: Surface newly added shows and real-time popular titles.
Core Components
- Indexing Engine: Elasticsearch or Solr tokenize and index metadata for fast search.
- Search API: Applies query filters, handles permissions, and returns ranked results.
- Autosuggest: Suggests matches based on partial typing, previous queries, and trends.
Handling Corner Cases
- Misspellings & Synonyms: Fuzzy search helps fix typos and match close terms.
- Large Catalog: Keeps indexing fast and efficient as content volume grows.
- Ranking Conflicts: Prioritizes results using popularity, personalization, and recent activity.
Detailed Discussion
Search & Discovery is often the first point of engagement. Combining personalized filters, trending insights, and fuzzy matching improves the chance users will find something to watch.
Real-time index updates ensure that new titles and trending content appear immediately. A fast, flexible, and intuitive search experience is essential for user satisfaction and retention.
8. Bonus Read: Typical User Flow
While the deep dive into the core services explains what each part of the system does, it can be equally illuminating to walk through how a user interacts with these services in a typical streaming session. In this bonus section, we explore the user flow in detail, from the moment they open the application to when they finish watching (or continue discovering) content. Each step reveals how the major services—Video Storage & Distribution, Playback, Recommendation, Search & Discovery, and Monitoring—collaborate to deliver a smooth and personalized experience.
1. User Opens App & Browses
-
Initial Data Retrieval: The moment the user opens the streaming application (be it a mobile phone, smart TV, or web browser), the client issues API calls to fetch user-specific data. This includes a list of recommended titles, the user’s “Continue Watching” queue, curated categories (“New Releases,” “Trending Now”), and possibly promotional banners for featured content.
-
Recommendation Engine Involvement: Before the user even interacts with the interface, the platform’s Recommendation Engine has assembled personalized content suggestions. If the user has a robust watch history, these recommendations will reflect recently watched genres or related shows. If the user is new, popular or regionally trending content might be displayed.
-
Search & Discovery: Alongside these recommended rows, the user interface typically features a search field or icon. The user may either rely on the recommended lists or decide to type in a search query immediately. However, many will first scan the homepage to see if something catches their eye.
Behind the scenes, the Monitoring & Logging pipeline tracks the user’s device type, app version, region, and the latency of each API call. If a certain region or device experiences slow response times, the logs and metrics can alert the operations team or trigger auto-scaling.
2. User Selects a Title
-
Playback Service Request: When the user chooses a specific title (e.g., a new movie or an episode of a TV series), the application calls an endpoint in the Playback Service. This call includes parameters such as the contentId, user authentication token, device capabilities, and possibly the resolution preference.
-
Entitlement & Region Checks: The Playback Service may validate that the user is in a region where that title is licensed. If the user is physically located somewhere that lacks the license, or if the user’s subscription tier doesn’t permit HD or 4K, the service might respond with an error or a downgraded set of streams.
-
DRM Key Acquisition: Assuming the user is authorized, the Playback Service fetches or generates a playback manifest (HLS .m3u8 or DASH .mpd) that references multiple bitrates. It also provides the user with the location of the DRM license server if the content is encrypted. The client-side player will soon request a DRM key, passing along user credentials and the content ID to ensure legitimate access.
At this point, the system logs a “play event” with the user’s account, time, and chosen title. The Recommendation Engine may consider this as a strong signal of interest in that content’s genre. Meanwhile, the user is seconds away from actually seeing any video.
3. CDN Video Delivery
-
Manifest Parsing: The client application receives the manifest from the Playback Service. This manifest lists the available variant streams—perhaps a 1080p, 720p, and 480p version, each encoded at different bitrates. The client chooses which variant to request first, often based on a quick test of network speed or user settings (e.g., “data saver” mode).
-
Edge Servers & Cache: The actual video segments (often 2-6 seconds each) come from CDN edge servers. The request might look like
httpGET https://cdn.myservice.com/content123/720p/segment001.ts.If the edge node already has that segment cached, it returns it immediately. Otherwise, it pulls the segment from the origin object storage, stores it temporarily, and then responds. -
Adaptive Switching: As the user’s network conditions vary, the client might jump to a higher bitrate for better quality or down to a lower bitrate to avoid buffering. All these segments are stored and served via the CDN. The user typically sees only a short buffering period before playback begins.
Throughout this delivery, Monitoring & Logging collects real-time stats like how long it takes to deliver each segment, the HTTP response codes, and whether the user’s device frequently switches bitrates. If there is a sudden spike in 404 errors, that might mean the CDN is misconfigured or an encoding job didn’t generate the correct segments.
4. User Interaction Logging
-
Play/Pause/Stop Events: As the user plays, pauses, or skips around in the timeline, those events are sent back to the platform’s analytics pipeline. The client typically batches these events for efficiency but will also send a final “stop” or “complete” event when the episode or movie finishes.
-
Feedback for Recommendations: If the user rates the title (e.g., thumbs up/down) or quits after two minutes, the Recommendation Engine sees that data. A short watch might indicate dissatisfaction. If many users drop out early, the platform might re-examine how that content is being promoted.
-
Session State: The user’s last watch position is also recorded. If they paused at minute 35, that timestamp is stored so that next time they open the app, they can continue. If the user spontaneously starts the same title from a different device, the Playback Service can automatically skip to minute 35.
In large-scale systems, this logging is typically done asynchronously. The client sends events to an endpoint that pushes them into a real-time pipeline like Kafka, and the data is eventually consumed by the analytics layer and the recommendation system. The user experiences minimal delay because the application never waits on any heavy data processing; it just collects data points and moves on.
5. Search or More Discovery
-
Return to Homepage: After finishing a show—or maybe partway through if they get bored—the user might go back to the homepage. The interface refreshes recommended rows, factoring in their latest watch event. If they watched a comedy, the system might highlight more comedies from the same decade or starring the same actors.
-
Search & Discovery: If the user is looking for something specific, they type in keywords or an actor’s name. The Search & Discovery Service, powered by Elasticsearch (or similar), quickly queries the index. Then it returns relevant titles sorted by popularity, user preference signals, or special promotions.
-
Trending & Personalized Suggestions: Sometimes, trending topics appear in a “Recommended Now” row, especially if a show just launched a new season. The user might be enticed to explore these recommendations. If they do, a new playback session begins, and the cycle repeats.
Notably, the “discovery” aspect can also happen passively. The homepage might highlight newly arrived content, shifting rows around as the user scrolls. All the while, the user’s micro-behaviors (how long they hover on a title, or if they skip reading the description) can be logged to refine content ordering or identify what truly grabs attention.
6. Deeper Observations of the User Flow
-
Cross-Device Continuity: Many modern streaming services let the user start watching on a phone, then pick up later on a TV. The service’s ecosystem unifies behind a single user ID, storing the session data (like last known position) so that the user’s experience is continuous.
-
A/B Testing: Streaming platforms commonly run experiments on the UI/UX. For instance, half of the users might see a different design for the “episode row” or different recommended categories on top. The system logs engagement metrics to see which interface or row ordering fosters higher watch times.
-
Real-Time vs. Batch Data: As soon as the user starts playing a new title, a real-time signal can reach the Recommendation Engine. However, more sophisticated re-ranking might wait for nightly batch processes or an hourly mini-batch that recalculates advanced user embeddings. The user might not see the full effect of their watch choice until the system has processed and integrated it into the recommendation model.
-
System Health: In each step, the platform carefully monitors both user experience (through metrics like “time to first frame” “average buffering events per 10 minutes” or “playback errors per minute”) and server-side health (CPU/memory usage, throughput, CDN hit ratios). If buffering spikes in a particular region, a custom logic might automatically route new segment requests to a less-congested edge node, or alert an on-call engineer.
7. Edge Cases in the User Flow
-
Inaccessible Titles: Sometimes, a user might see a show promoted on the homepage but then discover it’s unavailable in their region. The system might belatedly detect that the user’s IP or device region is mismatched for that license. Usually, large streaming platforms hide titles that are not available in a user’s region to avoid frustration.
-
Playback Failures: If the license server for DRM is down or network conditions are extremely poor, the user might see an error. Good design dictates that the app informs them gracefully: “We’re having trouble playing this right now” Meanwhile, the system’s logs quickly reveal the cause.
-
Simultaneous Streams: Some subscription plans allow multiple simultaneous streams. If the user attempts to open more streams than their plan permits, the Playback Service might deny the new session. This typically also shows up in logs and user-facing error messages.
-
Search Overload: The user might type a partial query that yields hundreds of results. The system’s search engine might only retrieve the top 20 or 30, applying ranking logic to present the most relevant ones first. If the user refines their query or adds more keywords, the system re-queries the index.
-
Account Sharing: In practice, multiple family members or friends might share the same account. This can blur the recommendation profiles, but the user flow remains largely unchanged at a technical level. Some platforms address this by encouraging or requiring separate profiles within the same subscription account.
8. Why This Flow Matters
-
Understanding the user flow is crucial because it shows how the microservices interact in real time. Each service—Storage & Distribution, Playback, Recommendation, Search & Discovery, and Monitoring—cooperates seamlessly:
-
Storage & Distribution ensures that no matter what the user picks to watch, the relevant segments are quickly accessible via the CDN.
-
Playback orchestrates the manifest and DRM, making sure the user can see the show without piracy concerns.
-
Recommendation influences the user’s content choices from the very start, while also consuming the watch data for continuous improvement.
-
Search & Discovery empowers the user to find new shows or hidden gems.
-
Monitoring & Logging stays active behind the scenes, capturing data that shapes operational decisions and resolves any issues quickly.
All these interactions emphasize how integral a robust architecture is for delivering a unified user experience. In the final analysis, no single microservice can provide the entire solution; the synergy between them is what creates an intuitive interface and top-tier streaming performance.
9. Addressing Non-Functional Requirements (NFRs)
A. Scalability & High Availability
-
Video Distribution: Use global CDNs or multi-CDN strategies.
-
Microservices: Each service scaled independently (Kubernetes or container-based).
-
Sharding & Replication: For metadata, search indexes, and recommendation data.
B. Performance & Low Latency
-
Adaptive Bitrate: Minimizes buffering by matching user bandwidth.
-
Caching: Store popular content or segments in edge servers.
-
Async Workflows: Transcoding and recommendation training done asynchronously, so user requests remain fast.
C. Security & DRM
-
DRM: Widevine, FairPlay, or PlayReady integrated with secure key exchange.
-
Geo-Blocking: Based on IP or user account region data.
-
User Data Encryption: TLS in transit, optional encryption at rest for sensitive data.
D. Reliability & Fault Tolerance
-
Redundant Storage: Multiple copies of content across regions.
-
Circuit Breakers: If a recommendation service is slow, degrade gracefully by showing fallback suggestions.
-
Retry Logic: For DRM license acquisition or partial content fetch failures.
E. Observability & Monitoring
-
Centralized Logging: Pipeline for all events, searching across microservices.
-
Metrics: Track QPS for each endpoint, concurrency, error rates, buffer rates.
-
Alerting: On high error thresholds or unusual concurrency spikes.
10. Bringing It All Together
By focusing on four key services — Video Storage & Distribution, Playback, Recommendation, and Search & Discovery — we create a modular, extensible architecture. Each microservice handles a critical piece of the streaming puzzle, scaling independently to serve massive global audiences.
-
This design parallels real-world streaming giants:
-
Video Storage & Distribution ensures encoded content is globally available with minimal latency.
-
Playback delivers adaptive streaming and DRM protection for uninterrupted viewing.
-
Recommendation uses user behavior data to generate personalized, dynamic suggestions.
-
Search & Discovery lets users rapidly locate and explore vast catalogs of content.
-
Logging & Monitoring maintains system health, ensures consistent performance, and drives iterative improvements.
By adhering to best practices in security, fault tolerance, and observability, this platform can reliably support millions of concurrent viewers around the world—offering high-quality streaming experiences, personalized content recommendations, fast search, and continuous monitoring for optimal uptime.
About the author: Ramesndra Kumar
Principal Engineer at Paytm, ex-Microsoft, system design coach, and mentor for top tech roles. Book time with them here.
Get Started
Linkedin & Resume Makeover
We will optimize your Resume & LinkedIn with our expert review & rewrite services.
Coaching Sessions
Our coaches will work with you on detailed, tailored sessions to get you ready for any challenge.
Negotiation Support
We will be by your side to review your contract & negotiate the salary you deserve.
Client Testimonials
Success stories from professionals who transformed their careers

"Hande's coaching was transformative. She didn't just help me prepare for Amazon's rigorous interviews—she made the process human, boostin..."

"All coaches gave me great tools to boost my confidence for my next interview process. Would definitely recommend."

"Interesting design problem, as always good advices regarding behavioural questions. A very good test before actually doing an interview o..."

"The lessons and guidance were appropriate to my needs and the expertise was thorough. The coaching was effective with homework. I landed ..."

"My coach was very helpful with insights on what I should focus on going into my phone interview."

"Arpitha is a truly fantastic coach, and helped tremendously with every aspect of the interview preparation, knowing what I need to focus ..."

"I am extremely grateful for the time and effort that Andrea invested in helping me improve my system design interview skills, and I would..."

"The Team of Andrea, Hande & Arpitha has been so good to me over the last fortnight they are incredibly accommodating to adapt to your sch..."

Ready to achieve similar results?
Find Your CoachSchedule your free consultation
Pick a time that works for you. In a short intro we’ll understand your goals and map out a plan to win offers.
- Quick intro (15–20 min) — no prep needed
- Share your target roles and timeline
- Get a personalized prep plan and next steps
- We’ll suggest the best coach to start with